Überblick
Ab April 2019 wurde die Funktion der Katalogsuche auf Elasticsearch aktualisiert. Dieses Upgrade bietet eine Reihe von Vorteilen, darunter die verbesserte Relevanz und Genauigkeit sowie eine dramatisch verbesserte Leistung - die Reaktionszeit ist viel konsistenter und im Allgemeinen doppelt so schnell. Diese neue Funktionalität wirkt sich auf die CMS-API, die Wiedergabe-API, die interaktive Studio-Suche und die Katalogsuchmethoden aus.
Während Brightcove erhebliche Anstrengungen unternommen hat, um Elasticsearch-Ergebnisse konsistent zu machen, gibt es Unterschiede, und es besteht eine geringe Möglichkeit, dass sich Ihre Integration möglicherweise nicht wie erwartet verhält, wenn Sie bestimmte Abhängigkeiten von Suchergebnissen codiert haben.
Unterschiede und Auswirkungen des Suchergebnisses
Bei der Untersuchung der potenziellen Auswirkungen hat Brightcove festgestellt, dass mehr als 90% der Suchanfragen Ergebnisse zurückgeben, die in Bezug auf die Anzahl der zurückgegebenen Ergebnisse übereinstimmen. Dies ist ein Indikator dafür, dass die erwarteten Ergebnisse nicht unterschiedlich genug sein sollten, um Probleme mit API-Integrationen zu verursachen.
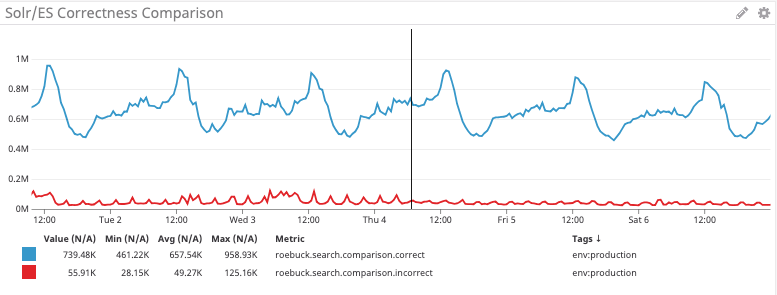
Diese Grafik zeigt die Anzahl der Suchergebnisse, die genau mit der Anzahl der Ergebnisse zwischen den beiden Systemen in Blau übereinstimmen, und denen, die sich in der Zahl in Rot unterscheiden.
Im Rahmen unseres Rollouts werden alle Standardsuchanfragen, diese Suchen nach der leeren Zeichenfolge, bereits seit mehreren Monaten von Elasticsearch bereitgestellt - so dass Benutzer Elasticsearch-Ergebnisse bereits ohne Probleme sehen und verwenden.
Es gibt jedoch Einschränkungen, was wir aus dieser Art von Vergleich lernen können. Im besten Fall können wir nur die Absicht einer bestimmten Suche ableiten, und Katalogdaten sind fließend.
Bekannte Unterschiede
Die folgenden Unterschiede sind weitgehend grundlegend oder das Ergebnis von Entscheidungen, die nach einer umfassenden Analyse der Suchergebnisse getroffen wurden - sie sind unmöglich vollständig zu beseitigen.
Stemming
Stemming ist der Prozess, bei dem gebeugte (oder manchmal abgeleitete) Wörter auf ihren Wortstamm, ihre Basis oder ihre Wurzelform reduziert werden - im Allgemeinen ein geschriebenes Wort bilden.
Ein Stemmer für Englisch, der am Stiel arbeitet Katze sollte solche identifizieren Saiten als Katzen , katzenartig Und katzenartig. Ein Stemming-Algorithmus könnte auch die Wörter fischen, fischen und fischen auf die Stammfische reduzieren. Der Stamm muss kein Wort sein, zum Beispiel reduziert der Porter-Algorithmus argumentieren , argumentiert , argumentiert , streiten Und Argus zum Stamm Argument.
Unsere bestehende Suche verwendet den Stemmer Lancaster (Paice / Husk). Dieser Algorithmus wird allgemein als übermäßig aggressiv angesehen - dies führt beispielsweise zu einer mangelnden Unterscheidung Feuerzeug und Licht würde unter Lancaster als der gleiche Begriff angesehen werden.
Elasticsearch verwendet einen neueren und viel weniger aggressiven Algorithmus (Porter2), der in der Industrie breite Akzeptanz gewonnen hat und allgemein als signifikante Verbesserung angesehen wird (Lancaster ist jetzt selten). Die Änderung der Wortstammerkennung wirkt sich möglicherweise auf einen erheblichen Anteil (~35 %) der Suchanfragen aus: Das heißt nicht, dass dies Ergebnisse sind Wille anders sein, nur dass sie könnte anders sein – aber im Allgemeinen sollte dies zum Besseren sein: Einige Untergruppen von Kunden verlassen sich möglicherweise auf das alte Verhalten.
Relevanz
Unsere bestehende Suche scheint eine strengere TF-Normalisierung zu haben. Dies bewirkt eine andere Relevanzsorte für Begriffe, die in größeren Feldern gefunden werden (d. h. existierende betrachtet die Übereinstimmung als weniger relevant, da sie dem Begriff weniger Gewicht verleiht, da er im Verhältnis zur Länge des Dokuments kleiner ist).
Sonderzeichen
Sonderzeichen werden in unserer bestehenden Suche entfernt, dies entspricht ziemlich dem Strippen von Interpunktionen und verwandten Zeichen - anstatt sie zu strippen, entkommen wir ihnen im Allgemeinen in Elasticsearch, daher besteht die Möglichkeit, dass eine Suche sie stattdessen berücksichtigt.
Begriff Handling
Bestehende Suchanfragen führen „term smooshing“ aus, während wir in Elasticsearch fehlerhafte Begriffe fallen lassen, betrachten Sie diese Suche mit einem leeren tags: Begriff: q=tags: state:ACTIVE
- Bestehende:
tags:state:ACTIVE— Suche nach Videos mit einem Tag vonstate:ACTIVE - Elasticsearch:
state:ACTIVE— lass den leeren Begriff fallen
Es gibt eine Reihe von subtilen Edge-Fällen im Zusammenhang mit der Behandlung von baumelnden Interpunktionen und Abfragen, die im Allgemeinen fehlerhaft sind. Wir versuchen zu produzieren, was die Abfrage unserer Meinung nach sein sollte, aber in diesen Fällen raten wir leider, was ein Benutzer beabsichtigt haben könnte (wann wir wirklich einen Fehler hätten zurückgeben sollen damit sie ihre Suche verfeinern können)
Nur spielbar
Es gibt zwei Mechanismen, um eine Suche auf Videos zu beschränken, die derzeit abspielbar sind: Die Abfrage kann ein Flag enthalten, oder die Abfrage selbst kann einen Aspekt der Spielbarkeit erfordern.
- Existing: Dies wird basierend auf dem Wert eines Feldes abgefragt, das aktualisiert wird
- Elasticsearch: Dies wird basierend auf berechneten Datumsbereichen abgefragt
Elasticsearch sollte im Allgemeinen genauer sein und bessere Ergebnisse erzielen (es gibt eine Verzögerung im Zusammenhang mit dem bestehenden Mechanismus, und der Flaggenwartungsmechanismus ist nicht vollständig zuverlässig).
Indexgenauigkeit
Der Elasticsearch-Index ist „frischer“ als der vorhandene Index und spiegelt Aktualisierungen tendenziell schneller wider - dies ist nicht immer der Fall, aber im Allgemeinen besteht die Erfahrung mit Elasticsearch darin, dass die Ergebnisse den Status der zugrunde liegenden Katalogdaten genauer widerspiegeln. Sowohl vorhandene als auch Elasticsearch sind verteilte Systeme und daher nicht vollständig konsistent in den Ergebnissen, die sie zurückgeben: Eine wiederholte Abfrage gegen beide Systeme kann möglicherweise unterschiedliche Ergebnisse liefern (insbesondere in dem Fall, in dem eine Reihe gleichzeitig ausgeführter Löschoperationen vorliegen).
Bestehende Suchergebnisse ändern sich basierend auf dem Status des Shards, dem ein Konto zugewiesen ist - der globale Status eines bestimmten Shard kann (und tut) die Ergebnisse einer bestimmten Abfrage beeinflussen: Elasticsearch hat diesen Mangel nicht.
Beispiele
Beispiel 1
Nehmen wir an, es gibt zwei Videos mit den folgenden Titeln:
Video#1: has the title “Don’t look into the light”
Video#2: has the title “Using a lighter to make a campfire”
Der Benutzer möchte alle Videos zurückgeben, die das Wort „Licht“ haben müssen. Mit der CMS-API würde die Abfrage wie folgt aussehen:
q=%2Blight or q=+light
Bei der bestehenden Suche werden beide Videos in der Reihenfolge zurückgegeben:
Video#2 - “Using a lighter to make a campfire”
Video#1 - “Don’t look into the light”
Es gibt zwei Probleme damit:
- Relevanz: Die Bestellung ist falsch. „Schau nicht ins Licht“ (Video #2) sollte erscheinen, bevor „Feuerzeug benutzt, um ein Lagerfeuer zu machen“ (Video #1)
- Genauigkeit: „Verwenden eines Feuerzeugs, um ein Lagerfeuer zu machen“ sollte nicht einmal in der Ergebnismenge erscheinen, da das Wort „Licht“ im Videotitel überhaupt nicht erscheint.
Mit Elasticsearch wird dies nur Video eins zurückgeben:
Video#1 - “Don’t look into the light”
Dies ist eine Verbesserung, weil:
- Relevanz: Die Reihenfolge ist korrekt.
- Genauigkeit: Es wird nur Video eins zurückgegeben, da es das einzige Video mit dem Wort „Licht“ im Titel ist.
Beispiel 2
Wie in unserer CMS-API-Dokumentation zum Einstemming beschrieben, wird Stemming unterstützt, aber keine teilweise Wortsuche. Nehmen wir an, es gibt 5 Videos mit den folgenden Titeln:
Video#1 - "Parking Ban Announced"
Video#2 - "Parking to be Banned"
Video#3 - "City Banning Parking"
Video#4 - "Bank Holiday"
Video#5 - "Bandit Captured"
Der Benutzer möchte alle Videos zurückgeben, die das Wort Ban im Namensfeld haben müssen. Mit der CMS-API würde die Abfrage wie folgt aussehen:
q=%2Bname%3Aban or q=+name:ban
Es wird erwartet, dass „Ban“, „Banning“ und „Banned“ zu Suchergebnissen führen würden, da „Ban“ ein Stamm aller drei ist.
Mit dem aktuellen Suchsystem werden jedoch alle fünf Videos in dieser Reihenfolge zurückgegeben:
Video#2 - "Parking to be Banned"
Video#3 - "City Banning Parking"
Video#1 - "Parking Ban Announced"
Video#4 - "Bank Holiday"
Video#5 - "Bandit Captured"
Auch hier gibt es zwei Probleme:
- Relevanz: Die Bestellung ist falsch. „Parkverbot angekündigt“ sollte das erste zurückgegebene Video sein, da es das Wort „Ban“ enthält.
- Genauigkeit: „Feiertag“ und „Bandit Captured“ sollten überhaupt nicht zurückgegeben werden, da „Ban“ nicht Teil des Wortes „Bank“ oder „Bandit“ ist.
Mit Elasticsearch sehen die Ergebnisse wie folgt aus:
Video#1 - "Parking Ban Announced"
Video#2 - "Parking to be Banned"
Video#3 - "City Banning Parking"
Dies ist eine Verbesserung, weil:
- Relevanz: Die Reihenfolge ist korrekt.
- Genauigkeit: Es werden nur Videos mit den Stielen des Wortes „Ban“ („Ban“, „Banning“ und „Banned“) zurückgegeben.